Neural Machine Translation - French to English
$\huge Neural\ Machine\ Translation$
Neural Machine Translation is the use of Deep Neural Networks for translating a text from one language (source language) to its counterpart in other language (target language).
In this notebook, we will use sequence to sequence modelling to translation French to English.
BIRD'S EYE VIEW OF THE BLOG¶
- Formulate the problem - Sequence to Sequence Approach
- Getting Acquainted with the Dataset
- Preprocessing and Preparing Text Data
- Define and Train the Model
- Inference
- Model Evaluation
1. Sequence to Sequence Modelling¶
A RNN is a feedforward network which uses internal memory (states) to process a sequence of inputs. RNN performs same computation on every input of data and the output is sent back intto the same network. Thus Recurrent Neural Networks use their reasoning from previous experiences to inform the upcoming events.
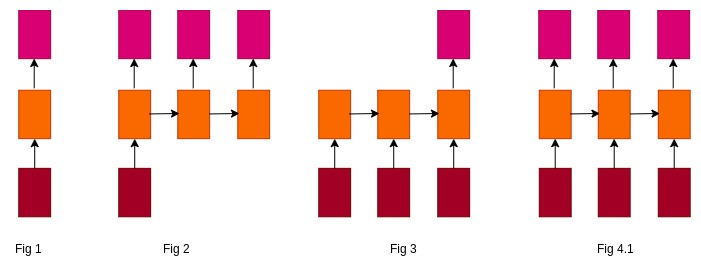
Let $T_x$ be the length of the input and $T_y$ be the length of the output. A variety of RNNs based on input and output length are :
- One to One (Fig 1) : $T_x\ =\ T_y\ =\ 1$
- Many to One (Fig 2) : $T_x\ >\ 1\ ;\ T_y\ =\ 1$
- One to Many (Fig 3) : $T_x\ =\ 1\ ;\ T_y\ >\ 1$
- Many to Many (Fig 4.1) : $T_x\ >\ 1\ ;\ T_y\ >\ 1$
Consider our task of French to English translation.
French Sentence : "je pense que vous vous etes tous rencontres"
English Translation : "i think that youve all met"
The architecture in Fig 4.1 can be applied when the length of the input and output are same. ($T_x$ = $T_y$). The French sentence consists of 8 words whereas its counter English translation consists of 6 words. To model such situations, instead of normal many-to-many architecture, we use sequence to sequence models. Seq2Seq is a many-to-many RNN architecture when $T_x\ !=\ T_y$
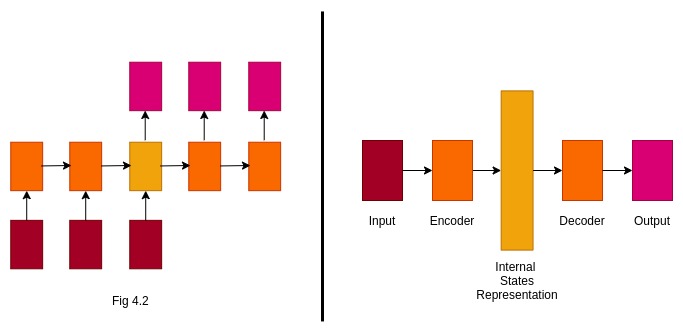
- Encoder -- The Encoder consists of RNN Units which encapsulates the data to a fixed size intermediate representation.
- Intermediate Representation -- It is the final hidden state produced by the encoder LSTM. It encapsulates the information of the input and helps the decoder to make predictions. It is fed as an hidden state input to the first cell of the LSTM- Decoder.
- Decoder -- The Decoder consists of RNN units. It accepts a hidden state from the previous unit and produces and output as well as its own hidden state.
# import important libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
import os
import string
from numpy import array
from pickle import dump
from unicodedata import normalize
import unicodedata
import unittest
import logging
import zipfile
from pathlib import Path
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from nltk.tokenize import sent_tokenize, word_tokenize
from PIL import Image
import pickle
from tqdm import tqdm
# for preparing text data
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.callbacks import EarlyStopping
# model-layers
from keras.layers import Input, LSTM, Dense, Embedding
from keras.models import Model
# plotting the defined model architecture
from keras.utils import plot_model
# word-cloud libraries
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from nltk.translate.bleu_score import sentence_bleu
from nltk.translate.bleu_score import SmoothingFunction
%load_ext nb_black
from IPython.display import HTML
display(
HTML("<style>.prompt{width: 0px; min-width: 0px; visibility: collapse}</style>")
)
# display(HTML("<style>.container { width:100% !important; }</style>"))
# declare constants needed for training the deep learning model.
# set the following parameter to True to limit the data used through the notebok
n_samples = False
# number of samples
NUM_SAMPLES = 20000
LATENT_DIM = 256
EPOCHS = 25
BATCH_SIZE = 25
# Initialise unittest instance object
tc = unittest.TestCase()
# Wordcloud paramters
MAX_WORDS = 600
MAX_FONT_SIZE = 120
version_name = "version1"
# initialize logger
logger = logging.getLogger("machine_translation")
logger.setLevel(logging.DEBUG)
# create console handler and set level to debug
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# create formatter
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
# add formatter to ch
ch.setFormatter(formatter)
# add ch to logger
logger.addHandler(ch)
2. Read and Explore Dataset¶
To learn sequence to sequence modelling for Neural Machine Translation, we have downloaded the Dataset with French phrases along with their English counterparts.
The dataset can be downloaded from: German- English Translations
OR
You can just run the cell below :)
The Tab-delimited Bilingual Sentence Pairs online page contains various language pairs. The sentences are selected from Tatoeba Project.
Each Dataset is represented in the following format : English + TAB + The Other Language + TAB + Attribution
Feel free to explore and experiment!
def download_data(
version_name="version1", destination_dir=os.path.join(".", "data", "fra-eng")
):
data_path = os.path.join(destination_dir, "fra.txt")
if not os.path.exists(data_path):
logger.debug(f"Creating directory tree - {destination_dir}")
Path(destination_dir).mkdir(parents=True, exist_ok=True)
!wget http://www.manythings.org/anki/fra-eng.zip
filename = os.path.join(destination_dir, "fra-eng.zip")
os.rename("fra-eng.zip", filename)
with zipfile.ZipFile(filename, "r") as zip:
logger.debug(f"Extracting the downloaded zip file - {filename} now...")
zip.extractall(destination_dir)
logger.debug(f"Done ! Downloaded {filename} at {destination_dir}")
else:
logger.debug(f"Data Available at the right path- {destination_dir}.")
# create directory to save model weights
if not os.path.exists(version_name):
Path(version_name).mkdir(parents=True, exist_ok=True)
return data_path
file_path = download_data()
raw_texts = pd.read_csv(
file_path,
encoding="utf-8",
sep="\t",
header=None,
names=["target", "input", "comments"],
usecols=["target", "input"],
)
display(raw_texts.head())
logger.debug(f"The shape of the data loaded : {raw_texts.shape}")
##visualising the French data using word cloud
cloud_text_input = str(list(raw_texts["input"]))
cloud_mask_input = np.array(Image.open("images/color1.jpg"))
cloud_title_input = "Most common words in French"
wordcloud = WordCloud(
background_color="white",
max_words=MAX_WORDS,
max_font_size=MAX_FONT_SIZE,
random_state=42,
mask=cloud_mask_input,
)
wordcloud.generate(cloud_text_input)
plt.figure(figsize=(10, 10))
image_colors = ImageColorGenerator(cloud_mask_input)
plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation="bilinear")
plt.title(cloud_title_input, fontdict={"size": 20, "verticalalignment": "bottom"})
plt.axis("off")
plt.tight_layout()
##visualising the English data using word cloud
cloud_text_input = str(list(raw_texts["target"]))
cloud_mask_input = np.array(Image.open("images/color2.jpg"))
cloud_title_input = "Most common words in English"
wordcloud = WordCloud(
background_color="white",
max_words=MAX_WORDS,
max_font_size=MAX_FONT_SIZE,
random_state=42,
mask=cloud_mask_input,
)
wordcloud.generate(cloud_text_input)
plt.figure(figsize=(10, 10))
image_colors = ImageColorGenerator(cloud_mask_input)
plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation="bilinear")
plt.title(cloud_title_input, fontdict={"size": 20, "verticalalignment": "bottom"})
plt.axis("off")
plt.tight_layout()


3. Text Data Preprocessing and Preparation¶
Data Preprocessing is an essential step in Machine Learning model. These steps performed on text data also significant in reducing dimensionality.
List of Preprocessing steps performed on each component of Text Data are :
- Removing Punctuations.
- Lowercasing - The raw texts consists of Uppercase and Lowercase letters. Thus the model may represent "hello" and "hEllo" with two different word vectors.
- French texts may contain special characters. They are converted to standard printables.
- Removing Extra Spaces.
def preprocess_texts(raw_text):
table = str.maketrans("", "", string.punctuation)
re_print = re.compile("[^%s]" % re.escape(string.printable))
clean_texts = []
for data_line in raw_text:
clean_text = (
unicodedata.normalize("NFD", data_line)
.encode("ascii", "ignore")
.decode("utf8")
)
##remove extra spaces
clean_text = clean_text.split(" ")
# change the words to lower
clean_text = [word.lower() for word in clean_text]
# remove punctuations
clean_text = [word.translate(table) for word in clean_text]
# remove non-printables
clean_text = [re_print.sub("", w) for w in clean_text]
clean_texts.append(" ".join(clean_text))
return clean_texts
preprocessed_data_path = os.path.join(
".", "data", "fra-eng", version_name, "preprocessed_fra-eng.csv"
)
if not os.path.exists(preprocessed_data_path):
preprocessed_data_dir = "/".join(preprocessed_data_path.split("/")[:-1])
Path(preprocessed_data_dir).mkdir(parents=True, exist_ok=True)
data_texts = raw_texts[["input", "target"]].apply(preprocess_texts, axis=0)
logger.debug(f"Saving Preprocessed Data to {preprocessed_data_path}")
data_texts.to_csv(preprocessed_data_path, index=False)
if n_samples:
data_texts = data_texts[:NUM_SAMPLES]
tc.assertEqual(len(data_texts), NUM_SAMPLES)
else:
data_texts = pd.read_csv(preprocessed_data_path)
if n_samples:
data_texts = data_texts[:NUM_SAMPLES]
tc.assertEqual(len(data_texts), NUM_SAMPLES)
logger.info(f"Read Preprocessed Data Successfully!")
Teacher Forcing¶
Tag the start and end of the target sentence using sos and eos respectively for training and inference¶
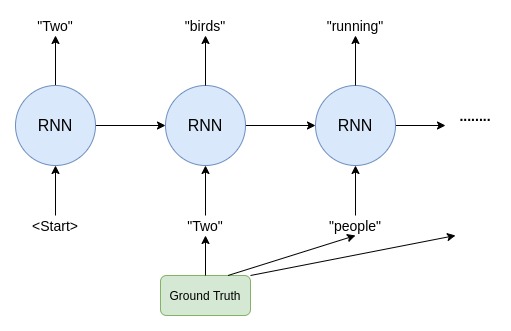
Sequence Prediction Models often use output from the last time step y(t-1) as input for the model at the current time step X(t). However during the early stages of learning, the hidden states of the model are often updated by a sequence of wrong predictions. Feeding this as an input to the current timestep causes errors to accumulate, and it is difficult for the model to learn from that.
Teacher Forcing remedies this by using the output in the prior time step(available in the training data) to compute the system state in the current time step. Instead of summing activations from incoming units, each unit sums correct teacher activations as input for the next iteration. It is a procedure for training RNNs with output to hidden recurrence which emerges from maximum likelihood criterion. Thus the model converges faster.
# manipulate data to support Teacher Forcing.
data_texts["decoder_input"] = "<sos> " + data_texts["target"]
data_texts["decoder_target"] = data_texts["target"] + " <eos>"
display(data_texts.head())
Split into training, validation and testing sets¶
data_train_texts, data_test = train_test_split(data_texts, test_size=0.2)
data_test_texts, data_valid_texts = train_test_split(data_test, test_size=0.5)
print(f"The Data Train split has {data_train_texts.shape[0]} records")
print(f"The Data Valid split has {data_valid_texts.shape[0]} records")
print(f"The Data Test split has {data_test_texts.shape[0]} records")
Create the dictionary for both source and target languages.¶
Now we have to feed these source and the corresponding target sentences to our Encoder-Decoder Model. We cannot work directly with the text. Therefore, we need to map the captions to numerical vectors.
To do this, an internal vocabulary(dictionary of words) from the list of texts must be constructed. This vocabulary should be constructed based on the word frequency. Now each sentence can be converted to sequence of integers based on this dictionary of words. So it basically takes each word in the text and replaces it with its corresponding integer value from the word-to-index dictionary.
To accomplish this task, we used the sophisticated API provided by Keras that can be fit on multiple documents ---Tokenizer.
- fit_on_texts - Fits list of texts on the Tokenizer object and updates internal vocabulary based on a list of texts. Lower integer means more frequent word. 0 is reserved for padding.
encoder_tokenizer_pickle_path = os.path.join(
".", "data", "fra-eng", version_name, "french_tokenizer.pkl"
)
decoder_tokenizer_pickle_path = os.path.join(
".", "data", "fra-eng", version_name, "english_tokenizer.pkl"
)
# train or load Tokenizers for encoder and decoder
if (not os.path.exists(encoder_tokenizer_pickle_path)) or (
not os.path.exists(decoder_tokenizer_pickle_path)
):
encoder_tokenizer = Tokenizer(filters="")
encoder_tokenizer.fit_on_texts(data_train_texts["input"])
decoder_tokenizer = Tokenizer(filters="")
decoder_tokenizer.fit_on_texts("<sos> " + data_train_texts["target"] + " <eos>")
with open(encoder_tokenizer_pickle_path, "wb") as handle:
pickle.dump(encoder_tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open(decoder_tokenizer_pickle_path, "wb",) as handle:
pickle.dump(decoder_tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
else:
with open(encoder_tokenizer_pickle_path, "rb") as handle:
encoder_tokenizer = pickle.load(handle)
with open(decoder_tokenizer_pickle_path, "rb",) as handle:
decoder_tokenizer = pickle.load(handle)
Word to Index and Index to Word Mapping¶
# word to index and index to word mapping for encoder
encoder_word2idx = encoder_tokenizer.word_index
encoder_idx2word = dict(map(reversed, encoder_word2idx.items()))
# word to index and index to word mapping for decoder
decoder_word2idx = decoder_tokenizer.word_index
decoder_idx2word = dict(map(reversed, decoder_word2idx.items()))
Total number of words in source and target dictionary¶
encoder_num_words = len(encoder_word2idx) + 1
logger.debug(f"The length of the encoder tokenizer dictionary is : {encoder_num_words}")
decoder_num_words = len(decoder_word2idx) + 1
logger.debug(f"The length of the encoder tokenizer dictionary is : {decoder_num_words}")
Calculate Maximum length in source and target sentence¶
To provides the fixed number of time steps to our encoder and decoder model we have to pad these sequence of numbers to maximum length. Therefore, we calculate the maximum length of sentences in both source as well as target language.
def max_length(desc1):
length = []
for sentence in desc1:
length.append(len(word_tokenize(sentence)))
return max(length)
encoder_max_length_pickle_path = os.path.join(
".", "data", "fra-eng", version_name, "french_max_len.pkl"
)
decoder_max_length_pickle_path = os.path.join(
".", "data", "fra-eng", version_name, "english_max_len.pkl"
)
if (not os.path.exists(encoder_max_length_pickle_path)) or (
not os.path.exists(decoder_max_length_pickle_path)
):
encoder_max_len = max_length(data_train_texts["input"])
decoder_max_len = max_length(data_train_texts["decoder_input"])
with open(encoder_max_length_pickle_path, "wb") as handle:
pickle.dump(encoder_max_len, handle, protocol=pickle.HIGHEST_PROTOCOL)
logger.debug(f"Encoder max length saved at {encoder_max_length_pickle_path}")
with open(decoder_max_length_pickle_path, "wb") as handle:
pickle.dump(decoder_max_len, handle, protocol=pickle.HIGHEST_PROTOCOL)
logger.debug(f"Decoder max length saved at {decoder_max_length_pickle_path}")
else:
with open(encoder_max_length_pickle_path, "rb") as handle:
encoder_max_len = pickle.load(handle)
with open(decoder_max_length_pickle_path, "rb") as handle:
decoder_max_len = pickle.load(handle)
logger.debug(f"Maximum Encoder seq length is {encoder_max_len}")
logger.debug(f"Maximum decoder Seq length is {decoder_max_len}")
Data Generator¶
def load_train_batches(data_train_texts, chunk_size=BATCH_SIZE):
index_tracker = 0
while True:
# retrieve the batch of input texts
input_train_text = list(data_train_texts["input"])[
index_tracker : index_tracker + chunk_size
]
# convert the extracted batch to sequences
train_x = encoder_tokenizer.texts_to_sequences(input_train_text)
# pad the input sequences to the max length
train_x = pad_sequences(train_x, maxlen=encoder_max_len, padding="post")
# retrieve the batch of decoder-input texts
target_train_input = list(data_train_texts["decoder_input"])[
index_tracker : index_tracker + chunk_size
]
# convert the extracted batch to sequences
train_y = decoder_tokenizer.texts_to_sequences(target_train_input)
# pad the sequences to the max length
train_y = pad_sequences(train_y, maxlen=decoder_max_len, padding="post")
# retrieve the batch of decoder-input texts
target_train = list(data_train_texts["decoder_target"])[
index_tracker : index_tracker + chunk_size
]
# convert the extracted batch to sequences
train_z = decoder_tokenizer.texts_to_sequences(target_train)
# pad the sequences to the max length
train_z = pad_sequences(train_z, maxlen=decoder_max_len, padding="post")
decoder_targets_one_hot = np.zeros(
(train_x.shape[0], decoder_max_len, decoder_num_words), dtype="float32"
)
# assign the values
for i, d in enumerate(train_z):
for t, word in enumerate(d):
decoder_targets_one_hot[i, t, word] = 1
index_tracker += chunk_size
if index_tracker >= len(data_train_texts):
index_tracker = 0
data_train_texts = shuffle(data_train_texts).reset_index(drop=True)
yield [train_x, train_y], decoder_targets_one_hot
def load_valid_batches(data_valid_texts, chunk_size=BATCH_SIZE):
valid_index_tracker = 0
while True:
# retrieve the batch of input texts
input_valid_text = list(data_valid_texts["input"])[
valid_index_tracker : valid_index_tracker + chunk_size
]
# convert the extracted batch to sequences
valid_x = encoder_tokenizer.texts_to_sequences(input_valid_text)
# pad the input sequences to the max length
valid_x = pad_sequences(valid_x, maxlen=encoder_max_len, padding="post")
# retrieve the batch of decoder-input texts
target_valid_input = list(data_valid_texts["decoder_input"])[
valid_index_tracker : valid_index_tracker + chunk_size
]
# convert the extracted batch to sequences
valid_y = decoder_tokenizer.texts_to_sequences(target_valid_input)
# pad the sequences to the max length
valid_y = pad_sequences(valid_y, maxlen=decoder_max_len, padding="post")
# retrieve the batch of decoder-input texts
target_valid = list(data_valid_texts["decoder_target"])[
valid_index_tracker : valid_index_tracker + chunk_size
]
# convert the extracted batch to sequences
valid_z = decoder_tokenizer.texts_to_sequences(target_valid)
# pad the sequences to the max length
valid_z = pad_sequences(valid_z, maxlen=decoder_max_len, padding="post")
decoder_targets_one_hot_valid = np.zeros(
(valid_x.shape[0], decoder_max_len, decoder_num_words), dtype="float32"
)
# assign the values
for j, d1 in enumerate(valid_z):
for k, word in enumerate(d1):
decoder_targets_one_hot_valid[j, k, word] = 1
valid_index_tracker += chunk_size
if valid_index_tracker >= len(data_valid_texts):
valid_index_tracker = 0
data_valid_texts = shuffle(data_valid_texts).reset_index(drop=True)
yield [valid_x, valid_y], decoder_targets_one_hot_valid
train_gen = load_train_batches(data_train_texts, chunk_size=BATCH_SIZE)
valid_gen = load_valid_batches(data_valid_texts, chunk_size=BATCH_SIZE)
4. Model Definition and Training¶
The RNN units in Encoder and Decoder can be RNN,GRU or LSTM cells. In this notebook we use LSTM.The heart of LSTM is it’s cell which provides memory. The cell is made up of three types of gates
Input Gate : Feeds the new information that we’re going to store in the cell state.
Output Gate : Provides the activation to the final output of the lstm block at timestamp ‘t’.
Forget Gate : Decides what information to throw away from the cell state.
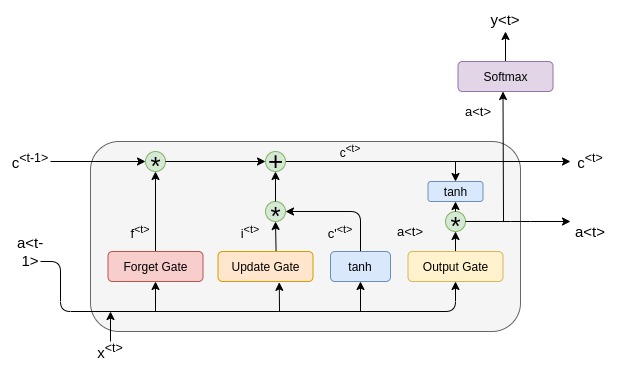
The equations of the LSTM gates are :
$i_t$ = $\sigma$($w_i$[$h_{t-1}$,$x_t$]+$b_t$) $f_t$ = $\sigma$($w_f$[$h_{t-1}$,$x_t$]+$b_f$) $o_t$ = $\sigma$($w_o$[$h_{t-1}$,$x_t$]+$b_o$)
where,
$i_t$ $\Rightarrow$ represents input gate $f_t$ $\Rightarrow$ represents forget gate
$o_t$ $\Rightarrow$ represents output gate $\sigma$ $\Rightarrow$ represents sigmoid function
$w_x$ $\Rightarrow$ weight for the respective gate(x) neurons $h_{t-1}$ $\Rightarrow$ weight for previous lstm block(at timestamp t-1)
$x_t$ $\Rightarrow$ input at current timestamp $b_x$ $\Rightarrow$ Biases for the respective gates(x)
The equations for the cell state, candidate cell state and the final output are :
$ \tilde{ct}$ = tanh($w_c$[$h_{t-1}$,$x_t$]+$b_c$) $c_t$=$f_t$ $c_{t-1}$ + $i_t$ $\tilde{ct}$ $h_t$=$o_t$ * tanh($c^t$)
where,
$c_t$ $\Rightarrow$ cell state(memory) at timestamp(t) $\tilde{ct}$ $\Rightarrow$ represents candidate for cell state at timestamp(t)
Note : represents the element wise multiplication of the vectors.*
Lastly, we filter the cell state and then it is passed through the activation function which predicts what portion should appear as the output of current LSTM unit at timestamp t.
We can pass this $h_t$ the output from current lstm block through the softmax layer to get the predicted output ($y_t$) from the current block.
# ENCODER
input_len = (encoder_max_len,)
encoder_input_layer = Input(shape=input_len)
# pass the input to emedding layer
encoder_embedding_layer = Embedding(encoder_num_words, LATENT_DIM)
encoder_embedding = encoder_embedding_layer(encoder_input_layer)
# Create a LSTM encoder and pass the input embeddings to it
encoder_lstm = LSTM(LATENT_DIM, return_state=True)
encoder_outputs, state_h, state_c = encoder_lstm(encoder_embedding)
# save the hidden states of the encoder
encoder_states = [state_h, state_c]
# DECODER
target_len = (decoder_max_len,)
decoder_input_layer = Input(shape=target_len)
# pass the input to emedding layer
decoder_embedding_layer = Embedding(decoder_num_words, LATENT_DIM)
decoder_embedding = decoder_embedding_layer(decoder_input_layer)
# Create a LSTM encoder and pass the input embeddings to it
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(LATENT_DIM, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_embedding, initial_state=encoder_states)
decoder_dense = Dense(decoder_num_words, activation="softmax")
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_input_layer, decoder_input_layer], decoder_outputs)
plot_model(model, show_shapes=True)

# Compile the deep learning model
model.compile(
optimizer="rmsprop", loss="categorical_crossentropy", metrics=["accuracy"]
)
if os.path.exists("modelv1_loss0.32.h5"):
model.load_weights("modelv1_loss0.32.h5")
else:
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=3)
machine_translate=model.fit_generator(train_gen,
steps_per_epoch=int(np.ceil(data_train_texts.shape[0] / BATCH_SIZE)),
validation_data=valid_gen,
validation_steps=int(np.ceil(data_valid_texts.shape[0] / BATCH_SIZE)),
callbacks=[es],
epochs=EPOCHS,
verbose=1)
model.save('modelv1_loss0.32.h5')
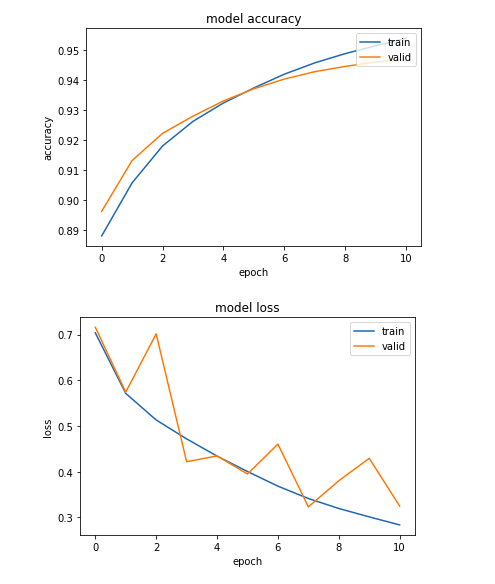
## summarize history for accuracy
plt.plot(machine_translate.history['accuracy'])
plt.plot(machine_translate.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'valid'], loc='upper right')
plt.show()
# summarize history for loss
plt.plot(machine_translate.history['loss'])
plt.plot(machine_translate.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'valid'], loc='upper right')
plt.show()
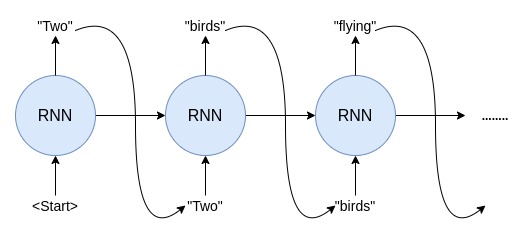
5. Inference¶
After the model is trained, it can be used to generate new sequences. To do that, we should feed a ”\< sos > ” token to the Decoder RNN along with the intermediate representation of the source sentence from the Encoder. The generated word in the output sequence will then be used as input on the subsequent time step along with the hidden states. The generation process will continue until the ”\< eos >” token is reached, or a maximum sequence length is reached.
encoder_model = Model(encoder_input_layer, encoder_states)
state_input_h = Input(shape=(LATENT_DIM,))
state_input_c = Input(shape=(LATENT_DIM,))
states_inputs = [state_input_h, state_input_c]
decoder_inputs_word = Input(shape=(1,))
decoder_inputs_word_x = decoder_embedding_layer(decoder_inputs_word)
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs_word_x, initial_state=states_inputs
)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs_word] + states_inputs, [decoder_outputs] + decoder_states
)
def decode_sequence1(test_sen):
# Encode the input as state vectors.
states_value = encoder_model.predict(test_sen)
target_seq = np.zeros((1, 1))
target_seq[0, 0] = decoder_word2idx['<sos>']
eos = decoder_word2idx['<eos>']
output_sentence = []
for _ in range(decoder_max_len):
output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
idx = np.argmax(output_tokens[0, 0, :])
if eos == idx:
break
word = ''
if idx > 0:
word = decoder_idx2word[idx]
output_sentence.append(word)
# Update the decoder input
# which is just the word just generated
target_seq[0, 0] = idx
# Update states
states_value = [h, c]
return (" ".join(output_sentence))
def evaluate_test_data(data_test_texts):
predicted_results = pd.DataFrame(
columns=["Input_Sentence", "Target_Sentence", "Predicted_Sentence"]
)
for seq_idx in range(len(data_test_texts)):
# retrieve the batch of input texts
input_test_text = list(data_test_texts["input"])[seq_idx : seq_idx + 1]
target_test_text = list(data_test_texts["target"])[seq_idx : seq_idx + 1]
# convert the extracted batch to sequences
test_x = encoder_tokenizer.texts_to_sequences(input_test_text)
# pad the input sequences to the max length
test_x = pad_sequences(test_x, maxlen=encoder_max_len, padding="post")
decoded_sentence = decode_sequence1(test_x)
predicted_results.loc[seq_idx] = [
data_test_texts.iloc[seq_idx]["input"],
data_test_texts.iloc[seq_idx]["target"],
decoded_sentence,
]
return predicted_results
predicted_results=evaluate_test_data(data_test_texts)
display(predicted_results[:10])
6. Model Evaluation¶
Now we have to provide a single numerical score to the translation generated which tells us how "good" our translation is when compared to the reference values.
Bilingual Evaluation Understudy - BLEU Score¶
BLEU is the standard machine translation (MT) evaluation metric which compares the machine generated translation to the set of good quality reference translations and counts the number of matches in a weighted fashion .BLEU score ranges between 0 and 1. The more the number of matches, the closer our translation is to the reference translations, the more BLEU score tends to 1. BLEU score is calculated on n-gram model.
\begin{equation} P_n\ =\ \frac{\sum_{ngram}\ Count\_Clip(n-gram)}{\sum_{ngram}\ Count(n-gram)} \end{equation}\begin{equation} Bleu\ Score\ =\ (B_p)\ *\ exp(\frac{1}{n}\ *\sum{1,n}P_n) \end{equation}where $B_p$ is the Brevity Penalty which is calculated as,
$$ f(n)= \begin{cases} 1&\mbox{if translation}\ output\ length > ref\ output\ length\\ \exp(1 - \frac{ref-output\ length}{translation-output\ length}),&\mbox{otherwise}\\ \end{cases} $$def calculate_sent_bleu(predicted_results):
# initialize lists for tracking bleu scores
bleu_1, bleu_2, bleu_3, bleu_4 = [list()] * 4
for i in range(len(predicted_results)):
hypothesis=predicted_results.iloc[i]['Target_Sentence'].split()
list_of_ref=[predicted_results.iloc[i]['Predicted_Sentence'].split()]
bleu_1.append(sentence_bleu(list_of_ref, hypothesis,weights=(1, 0, 0, 0),smoothing_function=SmoothingFunction().method2))
bleu_2.append(sentence_bleu(list_of_ref, hypothesis,weights=(0.5, 0.5, 0, 0),smoothing_function=SmoothingFunction().method2))
bleu_3.append(sentence_bleu(list_of_ref, hypothesis,weights=(0.33, 0.33, 0.33, 0),smoothing_function=SmoothingFunction().method2))
bleu_4.append(sentence_bleu(list_of_ref, hypothesis,weights=(0.25, 0.25, 0.25, 0.25),smoothing_function=SmoothingFunction().method2))
predicted_results['Bleu_1']=bleu_1
predicted_results['Bleu_2']=bleu_2
predicted_results['Bleu_3']=bleu_3
predicted_results['Bleu_4']=bleu_4
return predicted_results
result_try=calculate_sent_bleu(predicted_results)
print("BlEU-1 : ", result_try["Bleu_1"].mean())
print("BlEU-2 : ", result_try["Bleu_2"].mean())
print("BlEU-3 : ", result_try["Bleu_3"].mean())
print("BlEU-4 : ", result_try["Bleu_4"].mean())
# predicted_results.to_csv("./data/fra-eng/version1/modelv1_results.csv")